

My first experience with Lemmy was thinking that the UI was beautiful, and lemmy.ml (the first instance I looked at) was asking people not to join because they already had 1500 users and were struggling to scale.
1500 users just doesn’t seem like much, it seems like the type of load you could handle with a Raspberry Pi in a dusty corner.
Are the Lemmy servers struggling to scale because of the federation process / protocols?
Maybe I underestimate how much compute goes into hosting user generated content? Users generate very little text, but uploading pictures takes more space. Users are generating millions of bytes of content and it’s overloading computers that can handle billions of bytes with ease, what happened? Am I missing something here?
Or maybe the code is just inefficient?
Which brings me to the title’s question: Does Lemmy benefit from using Rust? None of the problems I can imagine are related to code execution speed.
If the federation process and protocols are inefficient, then everything is being built on sand. Popular protocols are hard to change. How often does the HTTP protocol change? Never. The language used for the code doesn’t matter in this case.
If the code is just inefficient, well, inefficient Rust is probably slower than efficient Python or JavaScript. Could the complexity of Rust have pushed the devs towards a simpler but less efficient solution that ends up being slower than garbage collected languages? I’m sure this has happened before, but I don’t know anything about the Lemmy code.
Or, again, maybe I’m just underestimating the amount of compute required to support 1500 users sharing a little bit of text and a few images?
The numbers are a little higher than you mention (currently ~3.2k active users). The server isn’t very powerful either, it’s now running on a dedicated server with 6 cores/12 threads and 32 gb ram. Other public instances are using larger servers, such as lemmy.world running on a AMD EPYC 7502P 32 Cores “Rome” CPU and 128GB RAM or sh.itjust.works running on 24 cores and 64GB of RAM. Without running one of these larger instances, I cannot tell what the bottleneck is.
The issues I’ve heard with federation are currently how ActivityPub is implemented, and possibly the fact all upvotes are federated individually. This means every upvote causes a federation queue to be built, and with a ton of users this would pile up fast. Multiply this by all the instances an instance is connected to and you have an exponential increase in requests. ActivityPub is the same protocol used by other federated servers, including Mastodon which had growing pains but appears to be running large instances smoothly now.
Other than that, websockets seem to be a big issue, but is being resolved in 0.18. It also appears every connected user gets all the information being federated, which is the cause for the spam of posts being prepended to the top of the feed. I wouldn’t be surprised if people are already botting content scrapers/posters as well, which might cause a flood of new content which has to get federated which causes queues to back up; this is mostly speculation though.
As it goes with development, generally you focus on feature sets first. Optimization comes once you reach a point a code-freeze makes sense, then you can work on speeding things up without new features breaking stuff. This might be an issue for new users temporarily, but this project wasn’t expecting a sudden increase in demand. This is a great way to show where inefficiencies are and improve performance is though. I have no doubt these will be resolved in a timely manner.
My personal node seems to use minimal resources, not having even registered compared to my other services. Looking at the process manager the postgres/lemmy backend/frontend use ~250MB of RAM.
For now, staying off lemmy.ml and moving communities to other instances is probably best. The use case of large instances anywhere near the scale of reddit wasn’t the goal of the project until reddit users sought alternatives. We can’t expect to show up here and demand it work how we want without a little patience and contributing.
Yup was just typing a comment to basically this effect. Federation adds a ton of overhead – you can still do things fairly efficiently, but every interaction having to fan out to (and fan in from!) many servers instead of like a single RDBMS is gonna cost you.
In all likelihood the code is not as efficient as it could be, but usually you get time to work those out gradually. A giant influx of users quickly turns “TODO: fix in the next six months” into “Oh god the servers are melting fuck fuck.”
That said, assuming the devs can get over this hump, I suspect using a compiled language will pay off long-term. Sure things will still be primarily IO-bound, but making things less CPU-bound is usually a good thing.
For some illustrative examples: Mastodon is in Ruby and hits dumb scaling limitations far more often than other fedi microblogs. Pleroma/Akkoma are Elixir (and BEAM is super well optimized for fast message passing/scaling/IO), Calckey (primarily Typescript) is moving some code to Rust, GoToSocial (Golang) is able to run in a fraction of the resources of Mastodon. The admins of one of the bigger tech instances recently announced they’re basically giving up on administrating Mastodon and are instead going to write a new server from scratch in a compiled language because it’s easier for them than scaling a Rails monolith.
TL;DR everything is IO-bound til it’s not.
I’m pretty sure the fediverse needs a new kind of node at some point. If we assume, that almost every larger instance is connected to almost every other larger instance directly, then there’s a ton of duplicated and very small messages.
There needs to be some kind of hub in-between to aggregate and route this avalanche. Especially if, like you wrote, every upvote is a message, the overhead (I/O, unmarshalling, etc) is huge.
This is kinda how Usenet worked (well, still does). Rather than n*n federated connections, smaller providers tend to federate with central hubs that form backbones.
I think it makes sense for the fediverse as well.
Hi, programming.dev owner here. From what I’ve been seeing it’s a lot of memory issues. We were hitting swap which was causing massive disk io. You can see what happened with the disk io immediately after the upgrade to more memory.
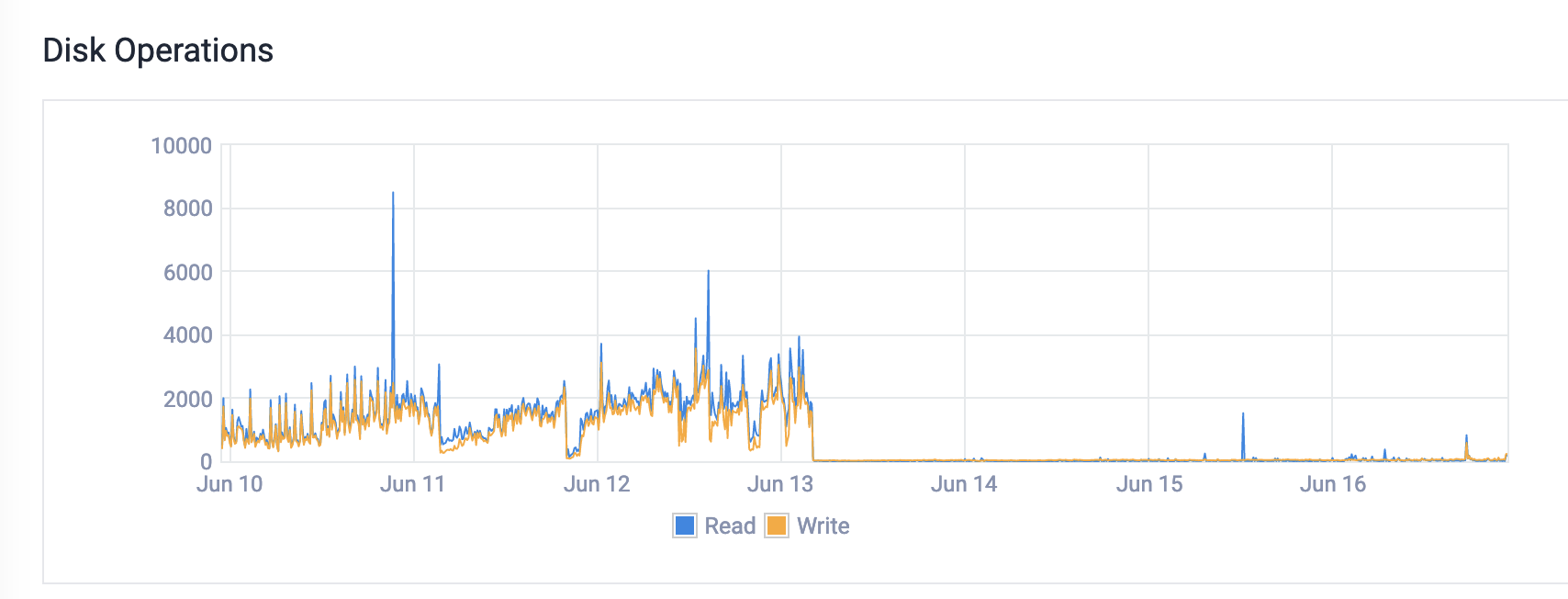 I know at least one reason is being resolved in this PR
I know at least one reason is being resolved in this PRWe were also having issues with the nginx config. There were some really weird settings that I don’t think were necessary. Finally, the federation is quite busy. So if someone subscribes to events from 10 different servers, we pull in every single event, even upvotes. There’s currently a lot of work being done around this stuff.
I don’t think Rust is the problem. I think it’s just a growth thing. Every platform has growth challenges, things grow in ways that you never expect. You might have thought that it was going to be IO constrained due to the federation, but in reality it’s memory constrained because memory is actually the most expensive thing to have on a server. etc.
It could be the devs just like programming in Rust. It’s a nice language lol
Whatever the performance bottlenecks are, I hope they can get them sorted so that any exponential growth caused by Reddit at the end of the month can be capitalized on.
I’ve got a feeling that other redditors who want to flee / branch out will look at these sites and so long as they see posts, comments and that it has a decent UI and loads well then people will stick around and build communities here.
I would say that it’s extremely unlikely.
Websites in general are never limited by raw code execution, they are mostly limited by IO. Be that disk IO as files are read and written, database IO as you need to execute complex queries to gather all the data to build the user timeline, and network IO to transfer data to and from the user. For decentralized social media like Kbin or Lemmy its even more IO limited as each instance needs to go back and forth to other instances to keep up-to-date data.
Websites usually benefit much more from caching and in-memory databases to keep frequently used data in fast storage.
This is why simple, high level, object oriented, garbage collected languages have become so common. All the CPU performance penalties they incur don’t actually affect the website performance.
In lemmy’s case, my perusal of the DB didn’t really suggest that the queries would be that complex and I suspect that moving it to a higher performance NoSQL DB might be possible, but I’d have to take a look at a few more queries to be sure.
I wonder if this could be made to work with Aerospike Community Edition…
Obviously it could be more effort than it’s worth though.
The real benefit as I see it for using rust for backends is memory safety.
All the major languages for web backends are memory safe. Java, C#, etc
These are garbage collected languages and come with the overhead of such a process. Rust has no GC process and instead relies on reference counters to statically track live memory.
“GC overhead” only matter for extreme realtime applications, like emulators, games, drivers, simulators, etc. a 10msec (or even a 100msec) pause in a request processing isn’t gonna even be noticed when your network, database and disk IO are literally orders of magnitude higher. Use Rust for web services if you like the language, comfortable with it, etc. Don’t use it because you think it’ll give you “more performance” or “reduce GC overhead”.
Java, C#, Python, Node, or even PHP as languages will never be your web backend bottleneck. Large scale web services performance tuning is entirely architectural. What caches you keep, how you organize your data, how many network operation does 1 user interaction translate to, stateful vs stateless components etc.
I think the devs openly stated they aren’t backend bods and asked for help optimising the database as a priority. There’s a bit of work going on on github to sort that out I think. Anyone reading this who can optimise postgresql or contribute to a database agnostic retool should probably speak to the devs as I imagine you’d be welcome.
I wish I could help so much but I doubt they’re going to retool into .net haha.
Which is fine. If they wanted to learn Rust and wrote inefficient code, good for them. I appreciate their efforts. Rust can certainly be beaten into shape and perform well enough in the end.
Rust itself or the way the Rust logic is implemented is not the bottleneck. Like most decent web applications the bottleneck is the database and how the decentralized protocols themselves are reconciled there.
Scaling massive amounts of records like Lemmy has been forced to is almost always IO bound at the database level even when a web service is centralized; this is much more difficult in federated architectures. This is why “NoSQL” databases have increased in popularity, but they are also not a magic bullet as there are major ACID trade offs one needs to consider.
I’m not convinced using rust is all that useful for web development. There are already plenty of other mature well optimized solutions for backend web development that includes a lot of security, qol features ootb like mature orm’s with optimized database access which regardless of how fast your code is can bottleneck your site much faster if you don’t have smart database access.
Yeah, theoretically rust can be faster than ruby/python/node, but it’s harder to optimize it enough to get to that point and you will have a much harder time finding devs to work on such a project because the amount of backend devs that have enough rust experience is so small, they’re like on the opposite sides of the ven diagram of languages for web developers.
On top of all that, languages which are heavily used for web development often get low level optimizations baked into the frameworks/languages so you can get pretty amazing performance uplifts over time to bring it to the level of lower level languages.






